docssetupeks upgrade readiness
EKS upgrade readiness
Two surfaces, both EKS-only, both pure read-only:
Two surfaces, both EKS-only, both pure read-only:
- Upgrade Insights — the
UPGRADE_READINESSinsights AWS produces from your cluster's audit log every day (deprecated APIs, add-on prerequisites, IAM and networking gotchas). Surfaced viaListInsights+DescribeInsight. - Managed node group AMI drift — current AMI release version per node group, plus how many days behind the latest AWS-published EKS-optimized AMI it is. Surfaced via
ListNodegroups+DescribeNodegroup, with a follow-on SSM (or EC2 fallback) lookup for the latest AMI.
Both surfaces ship as part of issue #103 and are paired in the UI on the cluster overview page so an operator preparing an upgrade can see "are my manifests OK and are my node images current?" in one place.
Backend-independent. These features are AWS-side API queries (eks:*, ssm:*, ec2:DescribeImages) — they do not touch the cluster's apiserver. They light up on any registered cluster as long as the cluster entry has both arn and region set, regardless of how Periscope authenticates to that cluster's K8s API. A common pattern: Periscope deployed inside an EKS cluster with backend: in-cluster (using the pod ServiceAccount for K8s auth) plus arn + region set so the same cluster also gets EKS Insights / Node Groups via the pod's IAM role. Same applies to agent-backed clusters — K8s traffic flows over the tunnel, AWS API traffic goes server→AWS directly.
What you see
Upgrade readiness card / page
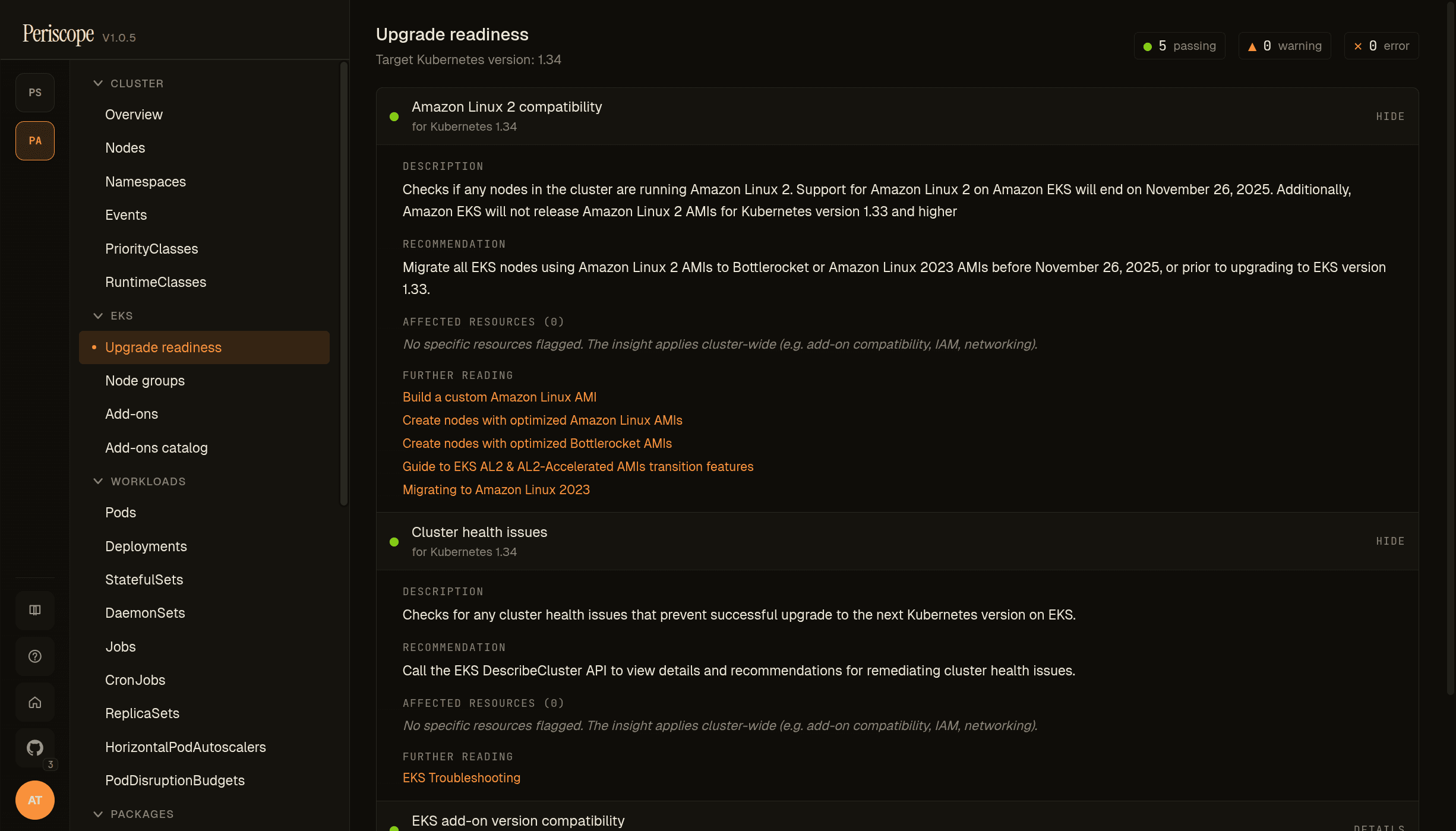
The page surfaces every UPGRADE_READINESS insight EKS publishes for the cluster — add-on version compatibility, kube-proxy / kubelet version skew, AL2 compatibility, cluster health. Each row shows a status pill (PASSING, WARNING, ERROR) and the count of affected resources.
Each insight expands to show its description, recommendation, the list of affected resources (when AWS flagged any), and further reading links to the relevant AWS docs. Affected-resource entries are deep links into Periscope's existing YAML editor — one click from "EKS flagged this" to editing the object.
Caveat — deprecated apiVersions: when AWS flags a resource at a deprecated apiVersion (e.g. policy/v1beta1 for a PodDisruptionBudget), the editor opens the resource at its currently-served version. This is generally what you want — you see live state. For CRDs at no-longer-served versions, the editor will surface a load error from the apiserver.
Node groups card / page
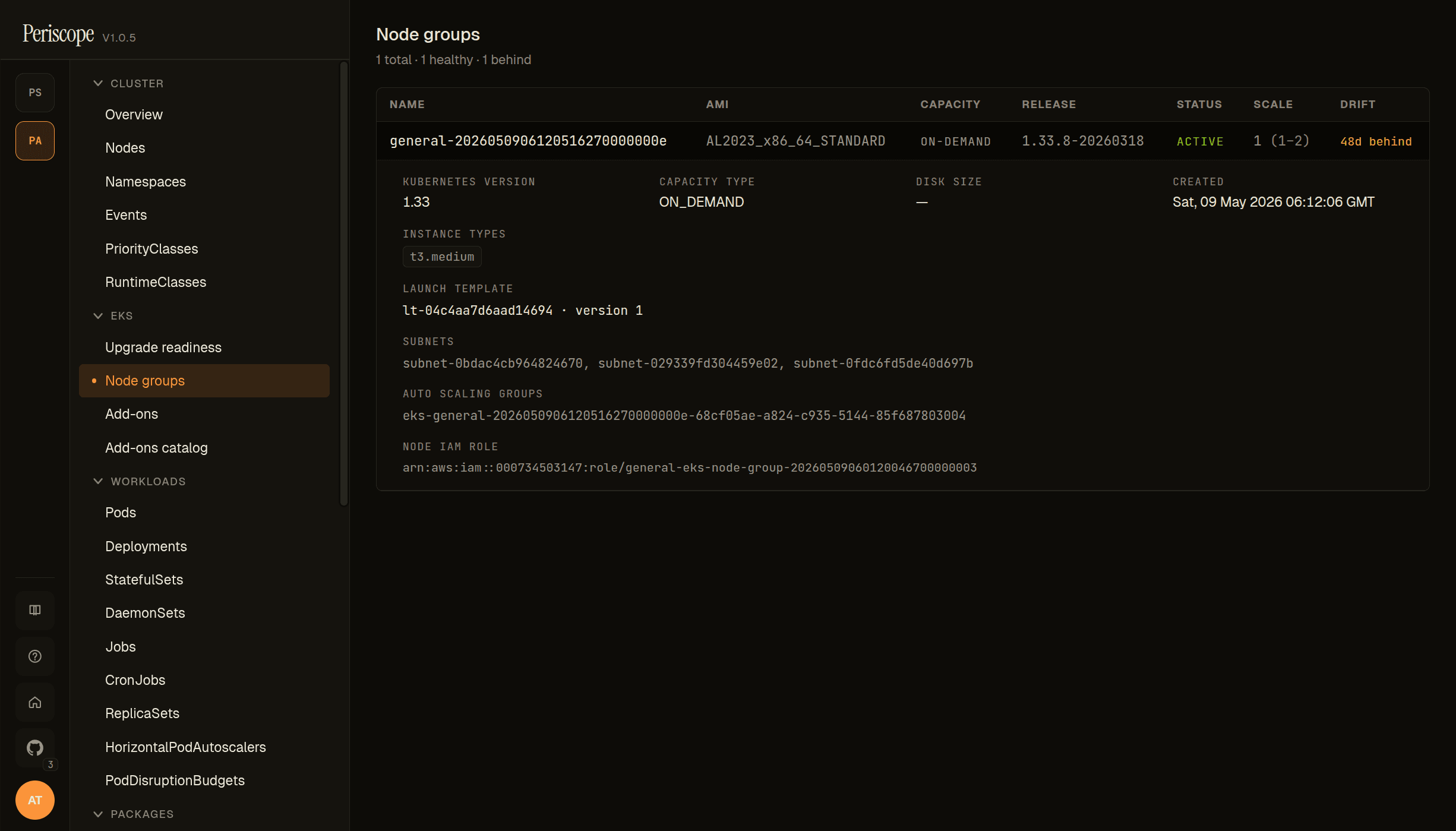
Each row carries the AMI type, current release version, and a drift cell — yellow Nd behind when the node group is older than the latest AWS-published EKS-optimized AMI for that K8s minor, green current when up to date, italic not tracked for AmiType=CUSTOM.
Custom-AMI node groups (AmiType=CUSTOM) are sorted first and explicitly badged "not tracked" — AWS does not publish a "latest" for custom images, so drift detection cannot apply.
IAM permissions
The periscope role (whether assumed via Pod Identity or IRSA — see deploy.md 4) needs the following actions for these surfaces:
| Action | Surface |
|---|---|
eks:DescribeCluster | always required (cluster auth path) |
eks:ListInsights, eks:DescribeInsight | Upgrade Insights |
eks:ListNodegroups, eks:DescribeNodegroup | Node groups (always) |
ssm:GetParameter (resource: arn:aws:ssm:*::parameter/aws/service/eks/* and parameter/aws/service/bottlerocket/*) | AMI drift (primary lookup) |
ec2:DescribeImages | AMI drift (fallback when SSM is denied / unavailable) |
The Insights and node group actions are read-only; nothing in this surface can mutate AWS state. The ssm:GetParameter resource scope intentionally matches only the public-parameter trees AWS publishes for EKS / Bottlerocket — it does not grant access to your own Parameter Store secrets.
Minimum policy snippet to add to the existing periscope role (extends the snippet in deploy.md 4.1):
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "EKSClusterScoped",
"Effect": "Allow",
"Action": [
"eks:ListInsights",
"eks:DescribeInsight",
"eks:ListNodegroups"
],
"Resource": "arn:aws:eks:*:111111111111:cluster/*"
},
{
"Sid": "EKSNodegroupScoped",
"Effect": "Allow",
"Action": "eks:DescribeNodegroup",
"Resource": "arn:aws:eks:*:111111111111:nodegroup/*/*/*"
},
{
"Sid": "SSMPublicAMIParameters",
"Effect": "Allow",
"Action": "ssm:GetParameter",
"Resource": [
"arn:aws:ssm:*::parameter/aws/service/eks/*",
"arn:aws:ssm:*::parameter/aws/service/bottlerocket/*"
]
},
{
"Sid": "EC2AMILookup",
"Effect": "Allow",
"Action": "ec2:DescribeImages",
"Resource": "*"
}
]
}eks:DescribeNodegroup is the one action in this set scoped to the nodegroup resource rather than the parent cluster — it lives in its own statement so the cluster-scoped wildcard above doesn't try to apply to it (AWS would return AccessDenied). The nodegroup/*/*/* wildcard matches nodegroup/<cluster>/<nodegroup-name>/<uuid>. ec2:DescribeImages only supports Resource: * because the API doesn't have resource-level ARNs for image lookups. The action is read-only.
Diagnosing missing permissions in the SPA. When the role lacks one of these IAM actions, the upgrade-readiness and node-groups pages render a permission-specific hint (Periscope's AWS role does not have permission to read…) instead of a generic red error banner. The backend translates AWS AccessDeniedException to HTTP 403 with the stable code E_AWS_FORBIDDEN; AWS ThrottlingException becomes 429 with E_AWS_THROTTLED (transient — refresh after a moment). All other AWS errors keep the legacy 502 / E_AWS_API shape.
Partition support. The IAM matrix above and the ec2:DescribeImages fallback list both Amazon-owned AMIs and the historical EKS-optimized AMI account 602401143452. This covers every AWS commercial region. GovCloud and China partitions are not covered for AMI drift detection in v1 — the EC2 AMI account IDs differ there, and the SSM /aws/service/eks/* parameter tree may not be published. The SPA will show "—" in the drift column for nodegroups in those partitions.
Refresh cadence
These caches are sized to AWS's own update frequency. The latency you see can be a multiple of the cache TTL on a fleet-wide refresh, but the underlying truth in AWS doesn't update faster than these intervals anyway, so polling more aggressively just burns API calls.
| Data | Source TTL | Cache TTL | Notes |
|---|---|---|---|
| Upgrade Insights list / detail | AWS refreshes daily | 1 hour | The first cache hit after a daily AWS refresh may still be stale by up to an hour. |
| Managed node groups (per cluster) | changes on operator action | 5 minutes | Short enough that a node-group rotation shows up promptly. |
Latest AMI for (family, k8sVersion) | AWS publishes new AL2023 EKS-optimized AMIs roughly weekly; Bottlerocket on its own cadence | 30 minutes | Shared across clusters — a fleet view of N AL2023 nodegroups makes one SSM call per (family, k8sVer) per half-hour. |
What is NOT in the surface
- Self-managed nodes (raw EC2, Karpenter, Fargate profiles). EKS only knows about managed node groups; self-managed nodes are invisible to
DescribeNodegroupand therefore invisible here. - Security advisories / CVEs against AMIs. There is no AWS API for "AMI X has CVEs Y/Z" — the data lives in HTML release notes (
awslabs/amazon-eks-amireleases, Bottlerocket security bulletins) and in account-scoped scan results (Inspector v2). We deliberately do not surface a CVE list here because faking one when AWS doesn't expose the data risks giving operators false confidence. The detail page links out to AWS's authoritative release notes; chase from there. - Windows + FIPS variants of the AMI catalog. The SSM parameter shape diverges (no
release_versionsubkey for Windows), and these variants are rare enough we'd rather punt than half-implement. Windows / FIPS node groups still appear in the list with their current AMI release version; the drift column reads "—".
NetworkPolicy
If you've enabled networkPolicy.enabled=true (see networkpolicy.md), Periscope needs egress to:
- the AWS EKS regional endpoints (already needed for
DescribeCluster) - the AWS SSM regional endpoints (for the AMI catalog)
- the AWS EC2 regional endpoints (for the drift fallback path)
All three are TCP/443. The most permissive default — "allow all internet HTTPS but no in-cluster traffic" — already covers them. For a tighter posture, list the regional endpoints you use explicitly; AWS publishes the IP ranges in the ip-ranges.json feed under service codes EC2 (covers EC2 + STS), AMAZON_CONNECT, and the regional AMI service.
Audit trail
Both surfaces emit a row to the audit log on every read, regardless of outcome:
verb=eks_insights_readfor the Upgrade Insights surfaceverb=eks_nodegroups_readfor the node groups + drift surface
These are the first read verbs in Periscope's audit taxonomy — every other verb (apply, delete, exec_open, secret_reveal, …) covers a privileged mutation. We added these specifically because compliance reviewers asked for a record of who looked at upgrade readiness before a version bump. Other read endpoints (helm list, resource list) remain unaudited.
Troubleshooting
Cross-cutting Periscope-pod issues live in troubleshooting.md. This section covers EKS-specific failure modes.
"Drift not computed" on every AWS-managed node group. Almost certainly an IAM issue. Check the periscope pod's logs for eks ami catalog: ssm lookup failed — the wrapped error names the missing permission. The 30-minute sticky-error cache means a fresh permission grant takes up to half an hour to take effect; restart the pod to apply immediately.
"Drift not computed" on Windows or FIPS node groups. Expected. The catalog does not cover those variants in v1; see What is NOT in the surface above.
Upgrade insights tab shows "load failed". The pod's role is missing eks:ListInsights / eks:DescribeInsight. The 422 path is for non-EKS clusters; a real load failure (5xx or 4xx other than 422) means the AWS call itself errored. The audit log has the full reason on the matching eks_insights_read row.
Affected resource link in an insight 404s. Two causes: (1) the deprecated apiVersion is no longer served by your apiserver — the editor's load failure is the genuine answer; or (2) the resource was deleted between the AWS daily scan and your click. Re-run the insights scan from the AWS console to refresh.