· featuresAn operator-grade console,
without the vendor lock.
Every page is built around how operators actually debug — list, drill, describe, exec, fix. No tabs you have to reorder, no plugin marketplace, no SaaS pricing per node.
01 / FLEET
Multi-cluster, in one pane.
Aggregates per-cluster status across every registered cluster in parallel — running under the user's impersonation, so a card error is per-card, not page-wide.
prod-eu-west-1●healthy
prod-us-east-1◐degraded
staging-edge-3●healthy
demo-kind-local○unknown
02 / WATCH STREAMS
Live, without F5.
SSE-backed list pages. Pods, events, configmaps, deployments, every registered kind. Last-Event-ID resume for proxy reconnects.
/api/clusters/prod/podslive
stream age14m 22s
events received1,847
resumed × Last-Event-ID3
03 / POD EXEC
A real shell, in the browser.
Streams stdin/stdout over WS. Idle, heartbeat, and session caps configurable per cluster. Every exec.attempted rows the audit log before the connection opens.
~ $ls /
bin data dev etc home
~ $█
04 / EKS INSIGHTS
Upgrade readiness, on-page.
AWS Insights + node group AMI drift + add-on freshness on a single dashboard. Not a separate console. Cached server-side; AWS only refreshes Insights daily anyway.
Upgrade readiness5 passing · 0 errors
Node groups1 healthy · 1 behind
Add-ons5 update available
EoSS countdown81d
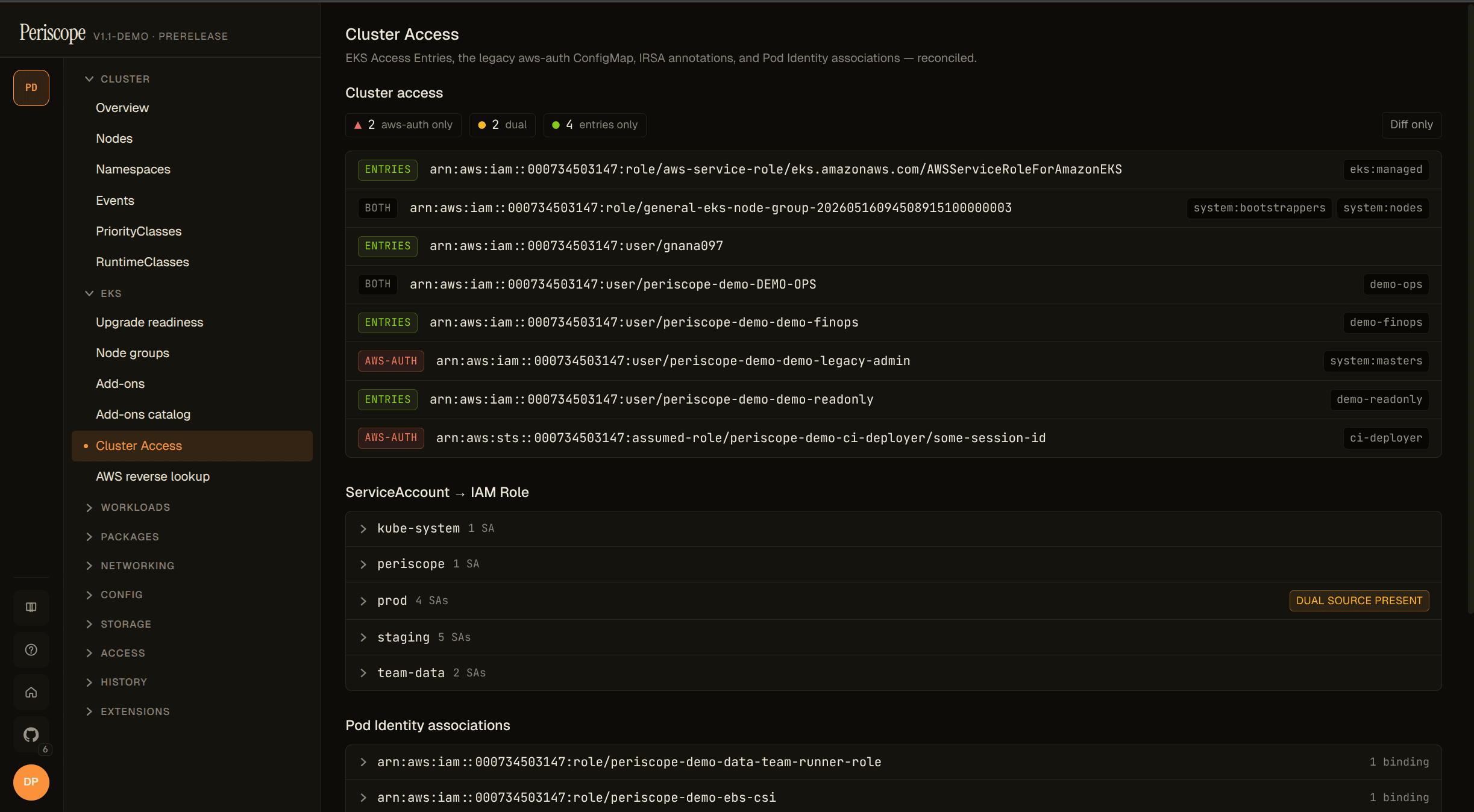
05 / AWS ACCESS
Who's reaching AWS, and how.
Cluster Access page reconciles Access Entries with the legacy aws-auth ConfigMap and unifies the SA → IAM Role index across IRSA and Pod Identity. Per-workload tab chips against an 18-action sensitive-permissions catalog. Reverse lookup answers which workloads can perform action X? in one query.
migration health12 aws-auth · 4 dual · 23 entries
payments-worker · proddual · pod-identity wins
iam:PassRole *priv-escalation
reverse: s3:DeleteBucket4 workloads
06 / HELM
Releases as first-class.
Read across secret + configmap drivers. Diff before upgrade, rollback in one click, values rendered with Monaco.
cert-managerv1.15.3 → v1.16.1
ingress-nginxup to date
metrics-serverv3.12.1 → v3.12.2
07 / AGENT
Zero inbound, by design.
The agent dials out over a long-lived WebSocket. No public LB, no IAM role per cluster. Works on EKS, GKE, AKS, on-prem k3s, kind — anywhere with outbound HTTPS.
tunnelconnected · 14m
mTLSverified
bootstrap tokenburn-on-attempt
08 / AUDIT
Every privileged action, rowed.
Stdout JSON sink + SQLite backend with retention caps. *.attempted before the K8s call, *.succeeded / *.failed after.
14:22:01pod.exec.attempted · ana@…
14:22:01pod.exec.succeeded
14:23:48helm.upgrade.failed
09 / IMPERSONATION
The dashboard isn't an admin.
Every K8s call sets Impersonate-Userto the human's OIDC sub. The bridge identity is only the transport credential; per-call authz is the user's RBAC.
SAR pre-flightenabled
disabled UI explains itselfyes
SA perms ≥ ceilinguser RBAC ≤ ceiling
10 / APPLY YAML
Monaco, dry-run, diff.
Paste or edit YAML in the embedded Monaco. Server-side dry-run shows the rendered diff before any mutation. The kubectl-apply path you'd already trust.
+ replicas: 5
- replicas: 3
· resources.limits.cpu: 500munchanged
11 / SECURITY
Vulnerabilities, grouped to act on.
Amazon Inspector v2 findings, joined to your pods and nodes, then grouped by package so 200 raw CVEs collapse to ~10 bumps with a suggested upgrade target per group. Filter to exploits or fixable only. Manual refresh emits one signed audit row. One Helm flag to enable.
go/stdlib1.16.1 → 1.26.3 · 116 CVEs
golang.org/x/crypto→ 0.45.0 · 7 CVEs
github.com/crewjam/saml3 exploits
12 / CLUSTER SHELL
kubectl, in the browser.
Per-session ephemeral pod on the target cluster, mounting a kubeconfig wired with your impersonate headers + tier-narrow resourceNames. Single audit row joins to the apiserver's own log via shared session-id. In-cluster and agent backends both.
$kubectl auth whoami
alice@corp[periscope-tier:admin]
$█
13 / NODE SHELL
A shell on the node. As you.
SSM Session Manager onto the node's EC2 host — kubelet, journald, containerd — no SSH key, no bastion. Opened with the operator's own short-lived AWS creds (OIDC id_token → AssumeRoleWithWebIdentity); the Periscope pod holds zero SSM permissions. CloudTrail attributes every session to the operator's IdP subject (the OIDC sub), not a shared role.
$whoami
ssm-usergeneric OS user
cloudtrail…/periscope-auth0|69f5…
14 / KARPENTER
NodePools, $/hr, drift.
Auto-detected dashboard: NodePool weights, disruption budgets, and per-pool $/hr + spot savings scraped from the controller. Pending pods carry the per-pool incompatibility reason from the FailedScheduling event — no grepping karpenter-controller logs.
default$1.84/hr · 71% spot
drifted claims2
pending pods3 · no instance type
disruption budgetok
15 / EKS ADD-ONS
Add-ons, upgrade-aware.
Installed add-ons with health, current vs latest version, the k8s compatibility window, and blocks next minor warnings. Catalog browse + install / upgrade / delete with a schema-aware config editor, under your impersonated identity.
vpc-cniv1.19.2 · current
corednsv1.11.1 → v1.11.4
aws-ebs-csihealthy
kube-proxyblocks 1.31